强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
时间:2023-06-28 06:13:19 来源:博客园
强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
1.核心词汇
深度确定性策略梯度(deep deterministic policy gradient,DDPG):在连续控制领域经典的强化学习算法,是深度Q网络在处定性”表示其输出的是一个确定的动作,可以用于连续动作环境;“策略梯度”代表的是它用到的是策略网络,并且每步都会更新一次,其是一个单步更新的策略网络。其与深度Q网络都有目标网络和经验回放的技巧,在经验回放部分是一致的,在目标网络的更新上有些许不同。
2.常见问题汇总
2.1 请解释随机性策略和确定性策略,两者有什么区别?
(1)对于随机性策略 $\pi_\theta(a_t|s_t)$ ,我们输入某一个状态 $s$,采取某一个动作 $a$ 的可能性并不是百分之百的,而是有一个概率的,就好像抽奖一样,根据概率随机抽取一个动作。
 (资料图)
(资料图)
(2)对于确定性策略 $\mu_{\theta}(s_t)$ ,其没有概率的影响。当神经网络的参数固定之后,输入同样的状态,必然输出同样的动作,这就是确定性策略。
2.2 对于连续动作的控制空间和离散动作的控制空间,如果我们都采取策略网络,应该分别如何操作?
首先需要说明的是,对于连续动作的控制空间,Q学习、深度Q网络等算法是没有办法处理的,所以我们需要使用神经网络进行处理,因为其可以既输出概率值,也可以输出确定的策略 $\mu_{\theta}(s_t)$ 。
(1)要输出离散动作,最后输出的激活函数使用 Softmax 即可。其可以保证输出的是动作概率,而且所有的动作概率加和为1。
(2)要输出连续的动作,可以在输出层中加一层tanh激活函数,其可以把输出限制到 $[-1,1]$ 。我们得到这个输出后,就可以根据实际动作的一个范围再做缩放,然后将其输出给环境。比如神经网络输出一个浮点数2.8,经过tanh激活函数之后,它就可以被限制在 $[-1,1]$ ,输出0.99。假设小车的速度的动作范围是 $[-2,2]$ ,那我们就按比例将之从 $[-1,1]$ 扩大到 $[-2,2]$ ,0.99乘2,最终输出的就是1.98,将其作为小车的速度或者推小车的力输出给环境。
3.面试必知必答
3.1 友善的面试官:请简述一下深度确定性策略梯度算法。
深度确定性策略梯度算法使用演员-评论员结构,但是输出的不是动作的概率,而是具体动作,其可以用于连续动作的预测。优化的目的是将深度Q网络扩展到连续的动作空间。另外,其含义如其名:
(1)深度是因为用了深度神经网络;
(2)确定性表示其输出的是一个确定的动作,可以用于连续动作的环境;
(3)策略梯度代表的是它用到的是策略网络。强化算法每个回合就会更新一次网络,但是深度确定性策略梯度算法每个步骤都会更新一次策略网络,它是一个单步更新的策略网络。
3.2 友善的面试官:请问深度确定性策略梯度算法是同策略算法还是异策略算法?请说明具体原因并分析。
异策略算法。(1)深度确定性策略梯度算法是优化的深度Q网络,其使用了经验回放,所以为异策略算法。(2)因为深度确定性策略梯度算法为了保证一定的探索,对输出动作加了一定的噪声,行为策略不再是优化的策略。
3.3友善的面试官:你是否了解过分布的分布式深度确定性策略梯度算法(distributed distributional deep deterministic policy gradient,D4PG)呢?请描述一下吧。
分布的分布式深度确定性策略梯度算法(distributed distributional deep deterministic policy gradient,D4PG),相对于深度确定性策略梯度算法,其优化部分如下。
(1)分布式评论员:不再只估计Q值的期望值,而是估计期望Q值的分布,即将期望Q值作为一个随机变量来估计。
(2)$N$步累计回报:计算时序差分误差时,D4PG计算的是$N$步的时序差分目标值而不仅仅只有一步,这样就可以考虑未来更多步骤的回报。
(3)多个分布式并行演员:D4PG使用$K$个独立的演员并行收集训练数据并存储到同一个回放缓冲区中。
(4)优先经验回放(prioritized experience replay,PER):使用一个非均匀概率从回放缓冲区中进行数据采样。
更多优质内容请关注公号:汀丶人工智能
标签:
最新文章推荐
- 强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
- 宁波培训机构(宁波靠谱的高级催乳师培训排行榜机构推荐) 天天快资讯
- 南宁市长湖路一餐厅火灾已被扑灭,无人员伤亡
- 望谟县平绕村:清理卫生死角 净化村域环境_实时焦点
- 【透视】美国财政部前高官:维系美国经济强韧的四大支柱,三根已动摇|全球观天下
- 【环球报资讯】sin30和cos30的关系_cos30 等于多少
- 杭州又有重磅展览来了!百余件敦煌文物即将登陆中国丝绸博物馆
- 全球百事通!隆下巴可以改善凸嘴吗_隆下巴多少钱
- 打印机维修教程网(打印机维修教程) 热文
- 世界热门:每体:因未能迎回梅西并且签下京多安,巴萨放弃阿姆拉巴特
X 关闭
资讯中心
 注意!海宁境内高速公路11月7日起实施差异化收费
注意!海宁境内高速公路11月7日起实施差异化收费
2022-12-30
2021-10-18
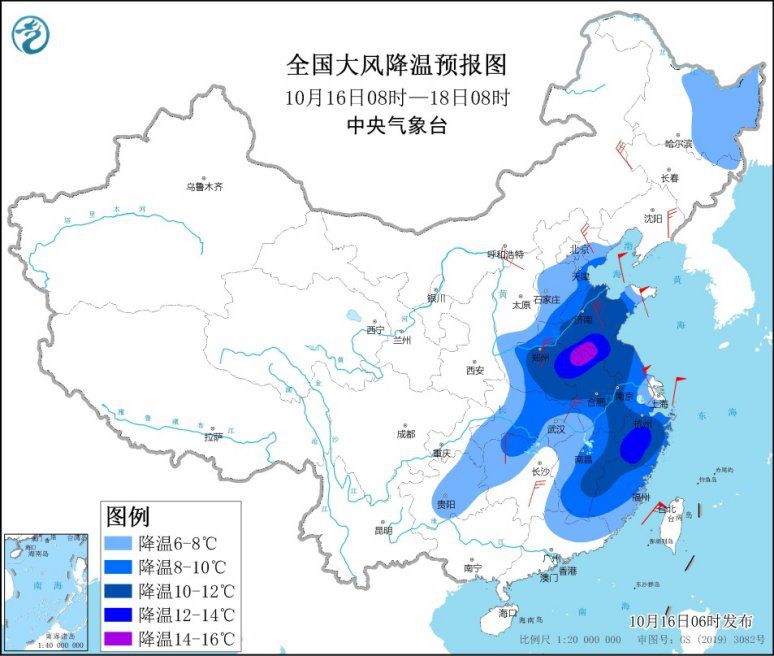 强冷空气继续影响中东部地区 局地降温14℃以上
强冷空气继续影响中东部地区 局地降温14℃以上
2021-10-18
 中东部多地将迎立秋后最冷周末 雨雪天气持续
中东部多地将迎立秋后最冷周末 雨雪天气持续
2021-10-18
X 关闭
热点资讯
-
1
刘向东:推动数实融合首先要增强数字经济服务实体经济的能力
-
2
上海籍阳性夫妻内蒙古密接、次密接者出现初筛阳性情况
-
3
内蒙古二连浩特:市民非必要不出小区、不出城
-
4
重庆一名潜逃24年的持枪抢劫嫌犯落网
-
5
销售有毒、有害食品 郭美美获刑二年六个月
-
6
陕西新增6名确诊病例1名无症状感染者 西安全面开展排查管控
-
7
《加强建设中国风湿免疫病慢病管理》倡议书:建立基层医院独立风湿科
-
8
游客因未购物遭导游辱骂?九寨沟:相关部门已介入调查
-
9
郭美美再入狱!销售有毒有害食品获刑2年6个月
-
10
2020年黄河青海流域冰川面积和储量较十年前缩减
-
11
5名“摸金校尉”落网 内蒙古警方破获一起盗掘古墓葬案